Acoustic Momentum
Weakly-supervised real-time crowd audio classifier for in-play sports pricing, achieving 12ms inference on Apple Silicon.
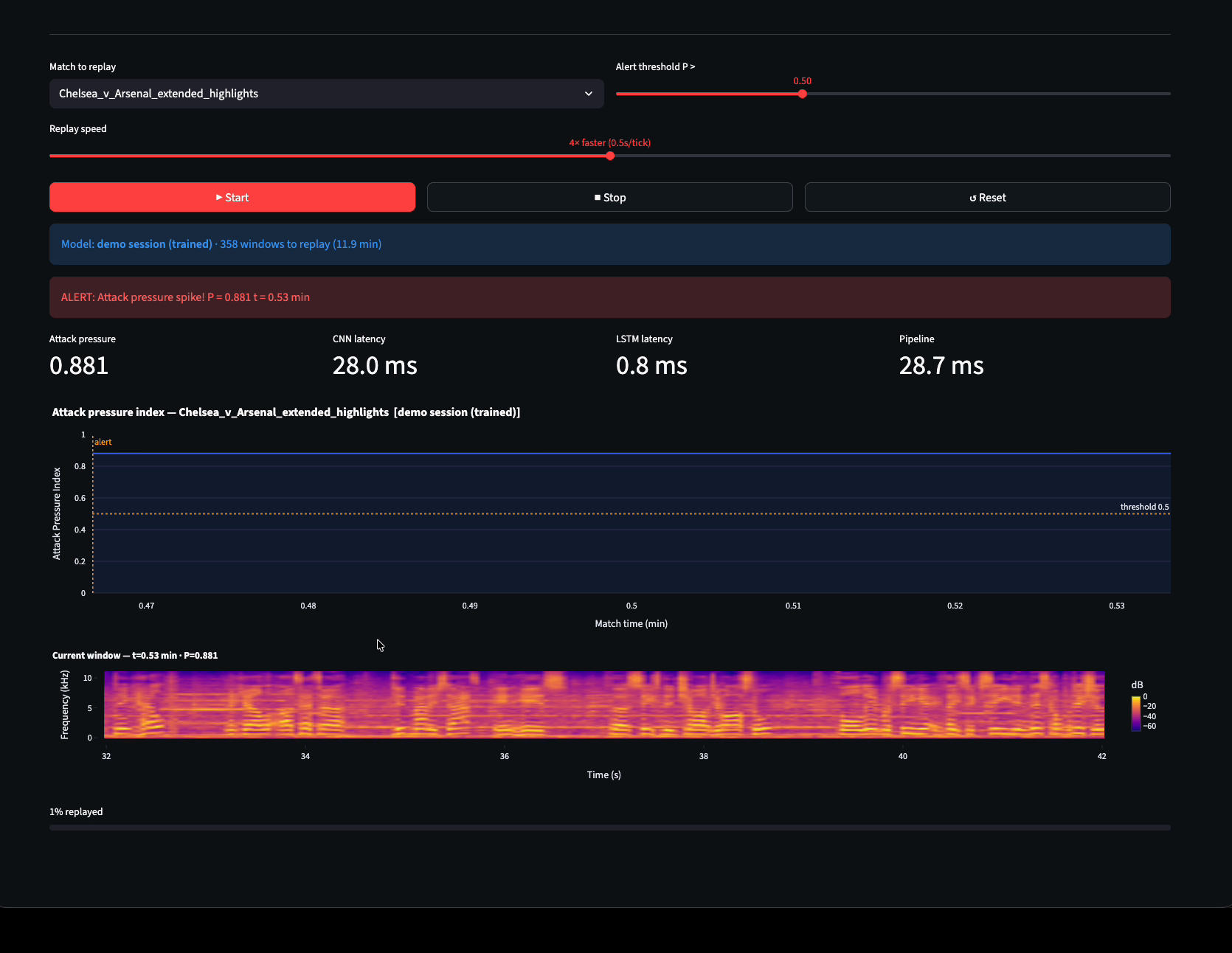
Acoustic Momentum turns raw stadium crowd audio into an Attack Pressure Index – a continuous [0,1] signal that fires during dangerous attacks, near-misses, and high-entropy game moments. The model is trained entirely from match audio plus goal timestamps via weak supervision, requiring no manual frame-by-frame annotation. This approach scales to thousands of hours of archive footage automatically using StatsBomb open data.
This is the companion project to GaitSignal: one modality from the crowd, one from the player. Both explore in-play information that the market may not yet fully price.
Key Features
- Weakly-supervised training from goal timestamps only – no manual annotation required
- 12ms end-to-end inference with ANE-optimized CNN + BiLSTM architecture on Apple Silicon
- Real-time live microphone monitoring via Streamlit dashboard for at-venue detection
- StatsBomb open data integration for automatic label generation at scale
- Honest edge analysis distinguishing exploitable from non-exploitable market tiers
Technical Architecture
The architecture is a mel spectrogram pipeline feeding an Apple Neural Engine-optimized depthwise-separable CNN encoder into a BiLSTM temporal head. The system uses a sliding window of 15 spectrograms (38 seconds of audio history) with strict causal time alignment – predictions are timestamped at the end of the last processed window, never using future audio. This achieves 12ms end-to-end inference on Apple Silicon.
The Streamlit dashboard provides three tabs: ingest (for processing match audio archives), training (for model iteration), and live monitoring (accepting microphone input for real-time detection). The project honestly analyzes which market tiers and strategies are realistically exploitable – lower leagues over Premier League, fade strategies over front-run (citing +4.1% per match from academic research).